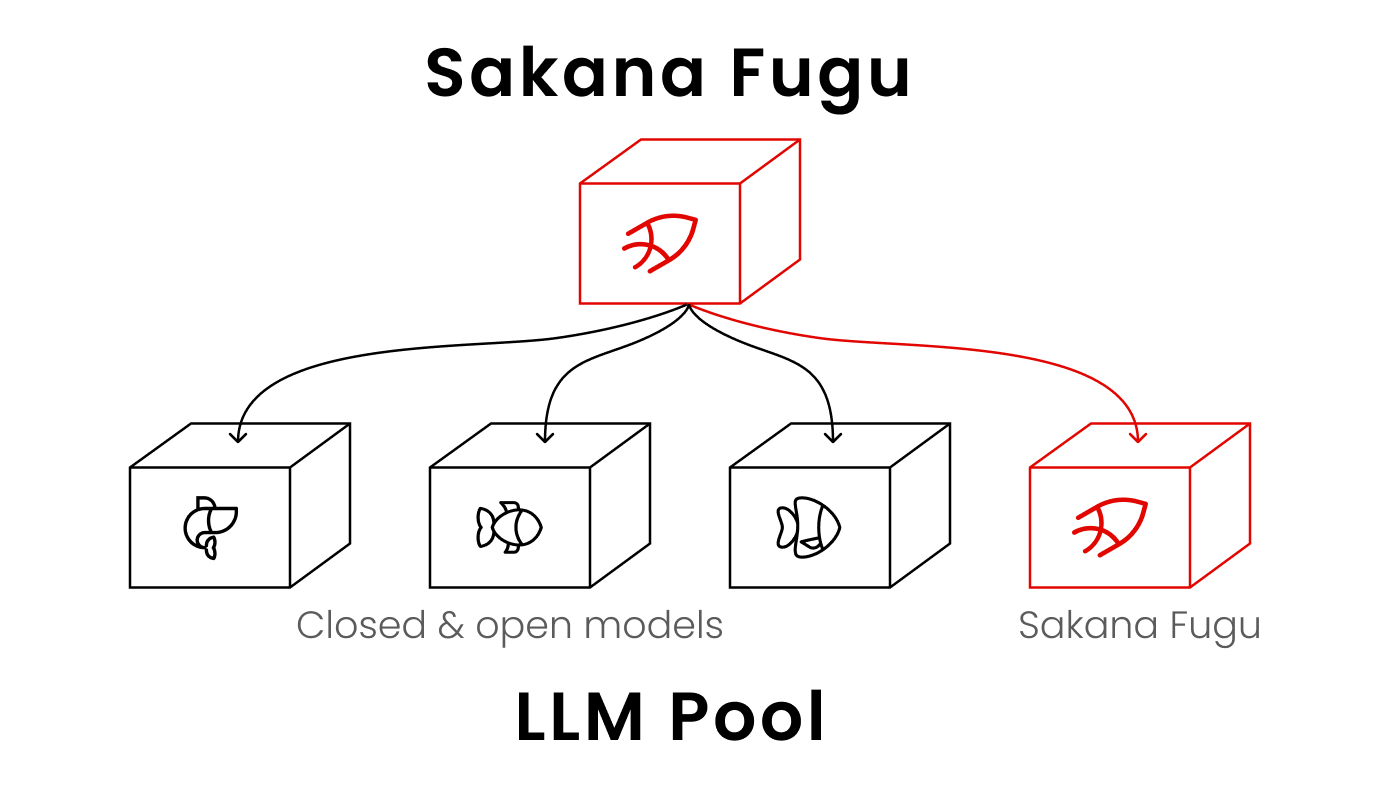
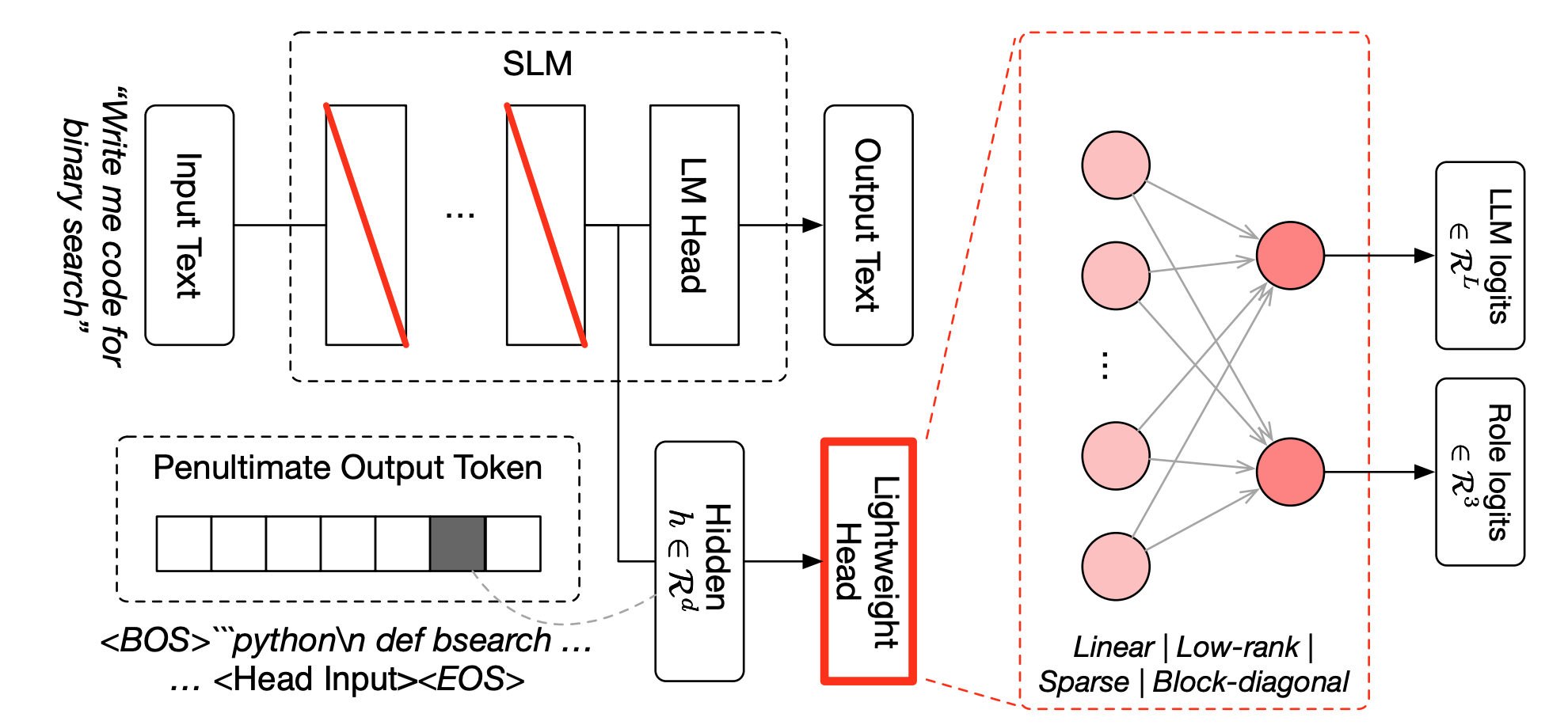
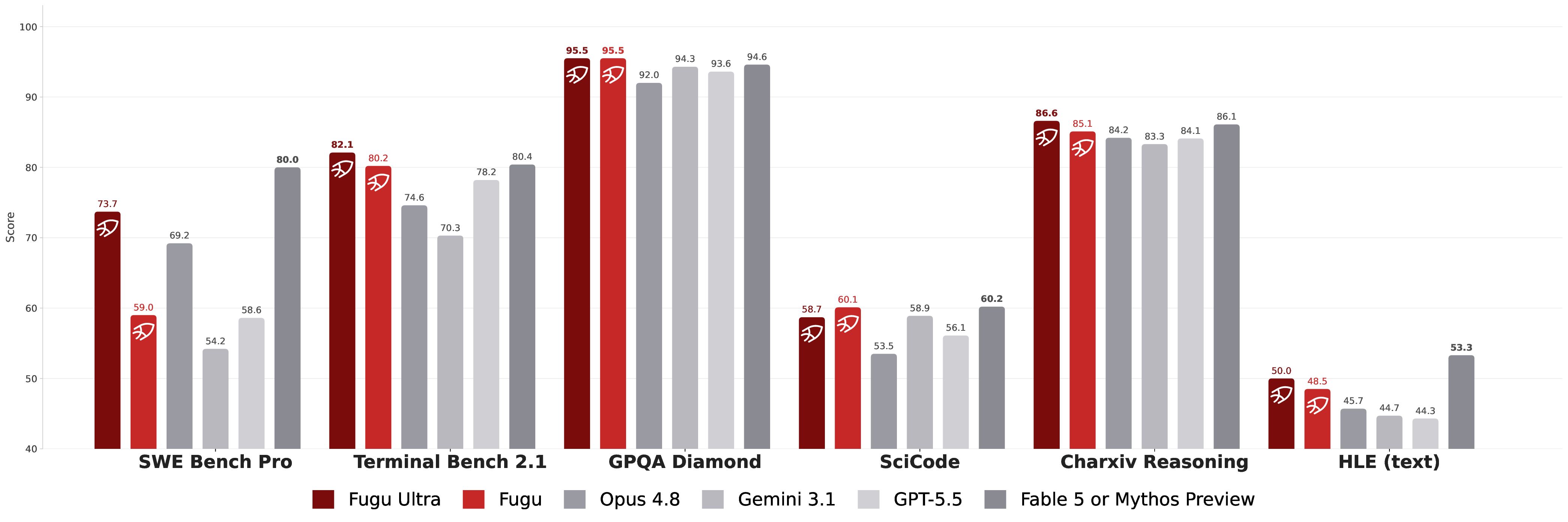
This experiment shows an AI agent autonomously improving a small GPT's training recipe. Using AutoResearch (Karpathy et al.) – which iteratively edits training code, runs experiments, and keeps only changes that lower validation bits-per-byte (BPB) – the agent ran 123 experiments over ~14 hours on a single H100 GPU. Each line traces a system's best BPB as experiments accumulate: Fugu-Ultra is in bold red (solid = mean over three seeds, dashed = best single run), with three frontier-model baselines (Model A, B, and C) faded behind it, and the callouts mark each new improvement the agent found on its own — spanning batch size, model depth, learning rates, and optimizer settings. Fugu-Ultra finishes with the best mean BPB (0.9774 ± 0.0019), ahead of Model C (0.9781), Model B (0.9793), and Model A (0.9822), and its best single run reaches 0.9748, leading every baseline. This suggests that orchestrating multiple strong models can outperform any individual frontier model on agentic ML research.例1 — AutoResearch / LLM学習
AIエージェントに小規模なGPTの学習レシピを自律的に改善させる実験。学習コードを反復的に書き換え、実験を実行し、検証用 bits-per-byte(BPB)を下げた変更だけを残していくエージェント型フレームワーク AutoResearch(Karpathy et al.)を用い、エージェントは単一のH100 GPU上でおよそ14時間にわたり123回の実験を実施した。各線は、実験が積み重なるにつれて各システムが達成した最良のBPBの推移を表している。Fugu-Ultra は太い赤の線(実線=3シードの平均、破線=最良の単一実行)で示し、その背後に3つのフロンティアモデルのベースライン(Model A・B・C)を淡色で重ねている。吹き出しは、エージェントが自ら見つけた改善点をそれぞれ示しており、バッチサイズ、モデルの深さ、学習率、オプティマイザの設定など多岐にわたる。Fugu-Ultra は最終的に最良の平均BPB(0.9774 ± 0.0019)を達成し、Model C(0.9781)、Model B(0.9793)、Model A(0.9822)を上回った。最良の単一実行では 0.9748 に到達し、すべてのベースラインを上回っている。これらの結果は、複数の強力なモデルをオーケストレーションすることで、エージェント型のML研究において単体のフロンティアモデルを上回り得ることを示唆している。
This case study tests whether the reading order of classical Japanese kana letters (仮名消息) can be recovered — letters whose scattered chirashigaki ("scattered-writing") layout makes that genuinely hard even for trained readers of classical Japanese. Each model is given the character bounding boxes together with a rough set of reading-order rules, and writes code that outputs the order the characters should be read in; here it runs on a letter written in 1610 by Hōshun'in (芳春院, 1547–1617), scored by NED (a score based on normalized edit distance from an expert's ground-truth order, where 1.0 is a perfect match). Several frontier models were put through the identical pipeline, but none came close to Fugu-Ultra on this letter: Model A reached only NED 0.24 and Model B scored no better, both far below Fugu-Ultra's 0.80, while Model C produced no predictor at all. The clip shows the two extremes — each panel draws its predicted path in red over the expert's ground truth in green: Fugu-Ultra (top) traces the letter almost exactly, while Model A (bottom) jumps all over the page. (Letter held by the Keio Institute of Oriental Classics.)例2 — 仮名消息の読み順推定
本ケーススタディは、仮名消息(古典日本語のかな書状)という歴史的資料における読み順の推定問題を対象とする。仮名消息は、文字を紙面に散らして記す「散らし書き」という形式で書かれているため、古文書を読み慣れた人でも文字の読み順を正しく判定することは難しい。そこで各モデルに対して、文字を囲む四角形(バウンディングボックス)と読み順の大まかなルールを与え、文字の読み順を推定するコードを出力させた。実験の対象には1610年に芳春院(ほうしゅんいん、1547–1617)が記した書状を選び、NED(専門家による正しい読み順との正規化編集距離にもとづくスコア。1.0が完全一致)で評価した。複数のフロンティアモデル(A-C)を同一のパイプラインに通したところ、Fugu-Ultraの結果は他のモデルを大きく引き離した。Model AはNED 0.24、Model Bもそれと大差なく、いずれもFugu-Ultraの0.80には遠く及ばない。さらにModel Cはまともなコードを一回も出力できなかった。モデルによる読み順の違いを可視化するために、専門家による正解の読み順(緑)の上に、推定した経路(赤)を描いて映像化した。Fugu-Ultra(上)が読み順をほぼ正確になぞる一方、Model A(下)は紙面全体をあちこち飛び回り、両者は大きく異なる結果を示している。 図:芳春院消息(慶應義塾大学斯道文庫蔵)
In this benchmark, each of Fugu-Ultra and 3 frontier models is given a single prompt to write a Rubik's Cube solver from scratch in pure Python — no off-the-shelf solving libraries allowed — and the resulting program is run locally on a held-out set of 300 randomly scrambled cubes. Solution quality is measured by the number of moves a solution uses, where lower is better. Fugu-Ultra and the frontier Model A wrote solvers that ran and solved all 300 cubes, while Model B and Model C each shipped sophisticated-looking code that crashed on execution and returned no valid solution at all (0/300). The clip follows cube #17: from the same scramble, Fugu-Ultra's solver reaches the solved state in 19 moves while Model A needs 21 — and across all 300 cubes Fugu-Ultra averages 19.72 moves versus 19.76 for Model A, both right at the optimal frontier, with Fugu-Ultra never a move longer than Model A on any cube (7 wins, 293 ties, 0 losses).例3 — ルービックキューブ・ソルバー
本ベンチマークでは、Fugu-Ultraと3つのフロンティアモデルそれぞれに、純粋なPythonのみでルービックキューブソルバーをゼロから実装するよう単一のプロンプトを与えた。既存のソルバーライブラリの使用は禁止とし、生成されたプログラムをランダムにスクランブルされた300個のキューブからなるホールドアウトセットに対してローカルで実行した。解法の質は手数で評価し、少ないほど良いとする。Fugu-Ultraとフロンティアの Model A は300個すべてのキューブを解くソルバーを生成したが、Model B と Model C は一見洗練されたコードを出力したものの、実行時にクラッシュし、有効な解を一つも返せなかった(0/300)。映像はキューブ#17の様子である。同一のスクランブルに対し、Fugu-Ultraのソルバーは19手で完成状態に到達したのに対し、Model A は21手を要した。300個全体の平均では、Fugu-Ultraが19.72手、Model A が19.76手と、いずれも最適解の水準にあり、Fugu-Ultraが Model A より手数が多かったケースは一度もなかった(7勝・293引き分け・0敗)。
Task: Create a mechanical iris in CAD, like a camera aperture, where multiple blades move together to open and close the central hole. For each model, we show both the generated detailed CAD itself and a simplified view that makes the structure easier to see. In the CAD generated by Fugu Ultra, the blades rotate around outer pins and clearly open and close the aperture. In contrast, the CAD generated by the other models shows problems such as gaps appearing, weak linkages, or the aperture not closing fully.例4 — CAD メカニカルアイリス
タスク:カメラの絞り(アパーチャ)のような、複数の羽根が連動して動き中央の穴を開閉する機械式アイリスをCADで作成する。各モデルについて、生成された詳細CAD(Detailed CAD)そのものと、構造を見やすくするための簡易ビュー(Simplified view)の両方を示す。Fugu Ultraが生成したCADでは、羽根が外側のピンを軸に回転し、アパーチャを明確に開閉できている。一方、他のモデルが生成したCADでは、隙間ができてしまう、リンク機構が弱い、アパーチャを十分に閉じきれていない、といった問題が見られる。
Four blindfold chess games, back to back. Every model plays the same way — no board shown — holding the full game in memory. Fugu outplays four strong opponents: three leading frontier models and a 2100-Elo Stockfish engine, staying accurate where they drift and ending each game in checkmate.例5 — 目隠しチェス
4局の目隠しチェスを連続して対局している。すべてのモデルは同じ条件でプレイし、盤面は一切表示されず、ゲーム全体を記憶の中に保持しながら指し手を進める。Fugu は4つの強力な相手——3つの主要なフロンティアモデルと、2100-Elo の Stockfish エンジン——を打ち負かした。相手が手を乱していく場面でも正確さを保ち、いずれの対局もチェックメイトで終えた。
This benchmark uses a single anonymized equity over one historical 50-week window and is intended to compare sequential, no-look-ahead decision-making rather than to establish generalizable trading performance. Past performance does not guarantee future results, and results may not transfer to other assets, time periods, or live markets. Each model makes online trading decisions on anonymized STOCK_X, using only current and past weekly market data: opening, high, low, and closing prices, volume, returns, moving averages, volatility, drawdown, portfolio state, and prior feedback. Starting with $10,000, the agent chooses whether to buy, hold, or sell, and what fraction of cash or shares to trade. After each action, the next week's price is revealed and the portfolio is updated, so the model must adapt from feedback rather than seeing the future. Across five runs of the identical 50-week pipeline, Fugu-Ultra grew the portfolio to $11,943.22 ± $633.86, a +19.43% mean return, while the other frontier models reached their return less than +15%.例6 — 株式トレーディング
匿名化された単一銘柄を1つの過去50週間のウィンドウで用いるこの株式トレーディングのベンチマーク。汎用的なトレーディング性能を立証するためではなく、先読みのない逐次的な意思決定を比較することを目的としている。過去の実績は将来の結果を保証するものではなく、結果が他の資産・期間・実際の市場に当てはまるとは限らない。各モデルは、匿名化された STOCK_X に対して、現在および過去の週次マーケットデータ——始値、高値、安値、終値、出来高、リターン、移動平均、ボラティリティ、ドローダウン、ポートフォリオの状態、直前のフィードバック——のみを用いてオンラインでトレーディングの意思決定を行う。1万ドルからスタートし、エージェントは買い・保有・売りのいずれかと、現金または株式のどの割合を取引するかを選択する。各アクションの後に翌週の価格が開示され、ポートフォリオが更新されるため、モデルは未来を見るのではなくフィードバックから適応しなければならない。同一の50週間パイプラインを5回実行した結果、Fugu-Ultra はポートフォリオを 11,943.22 ± 633.86 ドルまで成長させ、平均リターンは +19.43% に達した。一方、他のフロンティアモデルのリターンはいずれも +15% 未満にとどまった。